![]()

Künstliche Intelligenz in der Produktentwicklung im Spannungsfeld zwischen juristischer Perfektion und technischer Machbarkeit

- Christian Hartz
- Legal Engineer, Wolters Kluwer
Zitiervorschlag: Hartz, LRZ 2021, Rn. 260, [●], www.lrz.legal/2021Rn260.
Permanente Kurz-URL: LRZ.legal/2021Rn260
Dieser Beitrag befasst sich mit künstlicher Intelligenz in der Produktentwicklung und dem daraus resultierenden Spannungsverhältnis zwischen juristischer Perfektion und technischer Machbarkeit.
1. Einleitung
Spätestens seitdem die Europäische Kommission Ende April 2021 den Entwurf zum Artificial Intelligence Act1 vorgelegt hat, ist Künstliche Intelligenz wieder in aller Munde.2 Auch die juristischen Konferenzen haben das Thema 2021 vielfach aufgegriffen.
In diesem Beitrag werden die Besonderheiten der „Agilen KI-Produktentwicklung“ im juristischen Umfeld näher beleuchtet und über die Arbeit als Legal Engineer und Product Owner berichtet. Dieser Beitrag soll einen kurzgefassten Überblick über die Materie bieten.
2. Agile Entwicklung im Bereich Künstlicher Intelligenz
Agile KI-Produktentwicklung lässt sich nicht ohne einen Einblick in die Grundsätze von Agilität und der Produkt- und Softwareentwicklung erklären.
2.1. Agiles Projektmanagement
Agiles Projektmanagement ist nicht nur bei Softwareunternehmen ein häufig gewähltes Vorgehensmodell; auch in anderen Unternehmensbereichen kommt das Wort „agil“ oft vor. „Agile Unternehmensführung“, „agile Methoden“, „agiles Marketing“ oder „agile Transformation“ sind nur einige Beispiele. Mehrheitlich nimmt „agil“ dabei Bezug auf Konzepte des Agile Manifesto3 oder des Agile Marketing Manifesto4. Gemeinsam ist ihnen, dass sie eine Antwort auf das sog. VUCA-Unternehmensumfeld und die damit verbundenen Probleme bieten möchten. Diese leiten sich zuvorderst bereits aus dem Namen VUCA selbst ab, der für unbeständig (volatile), unsicher (uncertain), komplex (complex) und mehrdeutig (ambiguity) steht. Auch dem juristischen Projektmanagement ist der Begriff „agil“ immanent.5
2.2. Agile Produktentwicklung
Als Konsequenz aus dem agilen Projektmanagement und insbesondere auch im Zusammenspiel mit den Lean-Principles wird der Nutzer6 in das Zentrum (auch juristischer) Softwareentwicklung gerückt. Dieser user-centric approach verändert die Art und Weise, wie der Nutzer in den Entwicklungsprozess einbezogen wird. Im Lean-Ansatz wird der Nutzer insbesondere in der Discover- und Design-Phase stark involviert, um die geplante Software an dessen Bedürfnisse anzupassen; aber auch in den übrigen Phasen wird er durchgängig konsultiert:
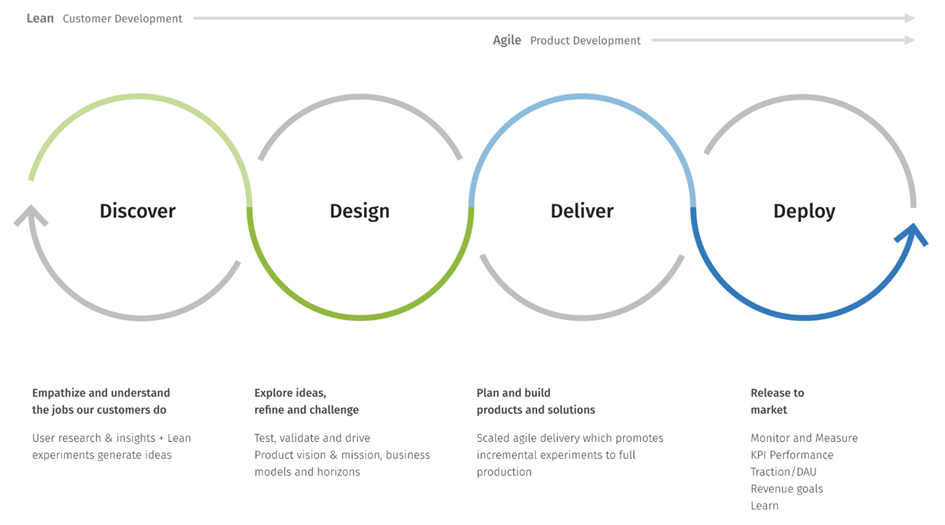
Ein weiterer Vorteil der agilen Produktentwicklung ist, dass mit jedem Zyklus eine Verbesserung des Produktes vorgenommen wird und so ein zusätzlicher Wert der Software in jeder Iteration geschaffen werden kann. Bei Softwareprodukten geschieht das i. d. R. durch das Ausliefern eines neuen Releases (einer neuen Version) der Applikation oder Softwarekomponente. Um dem agil arbeitenden Team die Fokussierung auf das Development zu ermöglichen, ohne, dass es sich Gedanken über die Produktionsstellung machen muss, wurde DevOps entwickelt. DevOps ist eine Verbindung der Wörter Development (Entwicklung) und Operations (IT-Betrieb). DevOps soll beide Bereiche so verknüpfen, dass es zu einem kontinuierlichen Entwicklungs- und Auslieferungsprozess (Continuous Integration/Continuous Deployment (Delivery) oder kurz CI/CD) kommt.
2.3. Auch der künstlichen Intelligenz in der Produktentwicklung ist dieser „agile“ Ansatz immanent
Bei der Entwicklung von KI-Applikationen steht auch der Nutzer im Zentrum des Fokus. Den größten Einfluss auf das Ergebnis hat aber der Responding to change-Prozess aus dem Agilen Manifest der Softwareentwicklung: diesen Prozess zeichnen schnelle Iterationen aus, bei denen mehrere Experimente mit zunächst unklarem Ausgang durchgeführt werden. Das Ziel dieses Prozesses ist das Finden des Algorithmus mit den besten Metriken. Gleichzeitig gilt dabei das Paradox, dass der Algorithmus, der heute noch das beste Ergebnis geliefert hat, morgen bereits veraltet sein kann und durch ein besseres Modell ersetzt werden muss. Die angesprochenen Aspekte aus dem VUCA-Begriff, insbesondere die Volatilität, haben somit gerade bei der KI-Entwicklung einen noch größeren Einfluss als im klassischen Unternehmensumfeld.
Der Entwicklungsprozess in einem KI-Projekt erfolgt entsprechend iterativ und lässt sich in folgendem Lebenszyklus darstellen:
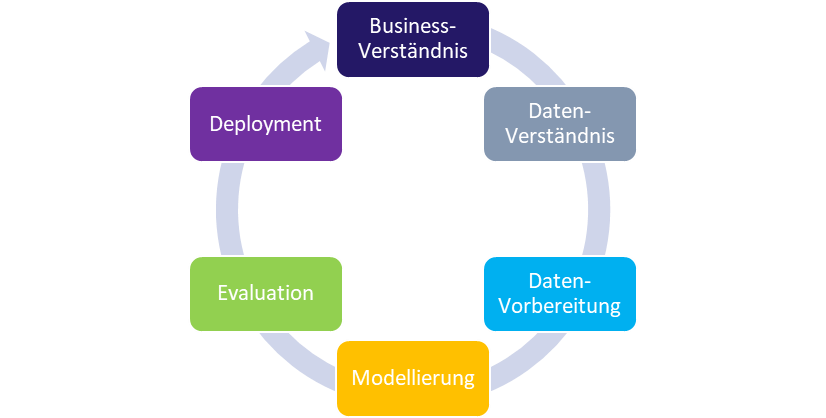
Das Business-Verständnis ist von zentraler Bedeutung; ihm folgend werden Ziel und zu schaffender Wert festgelegt. Gleichzeitig dient es auch als Kompass für das Entwicklungsteam, anhand dessen jegliche Entscheidung verifiziert oder falsifiziert werden muss.
Eine weitere Komponente ist das sog. Daten-Verständnis, das häufig im Rahmen einer Explorativen Datenanalyse (EDA) aufgebaut wird. Teil der EDA sind auch simple Statistiken über Daten wie Satzlänge oder die am häufigsten verwendeten Wörter.
Nach dem Aufbau des Daten-Verständnisses beginnt der Prozess der Daten-Vorbereitung. Der Aufwand dieses Prozesses sollte keinesfalls unterschätzt werden. Gelingt es häufig noch, Beispielsdaten für ein grundlegendes Datenverständnis kurzfristig zusammenzustellen, muss spätestens jetzt der vollständige Datensatz vorliegen, um die nachfolgende Modellierung planen zu können. Genau an dieser Stelle liegt ein wesentlicher Unterschied zwischen der KI-Produktentwicklung und einer „normalen Produktentwicklung“. Liegt die Schöpfung in der „normalen Produktentwicklung“ im (iterativen) Schreiben von Programmcodes auf Basis eines festgelegten Ziels, kommt bei der Entwicklung im KI-Bereich hinzu, dass genügend Daten gefunden und zusammengetragen werden. Im juristischen Umfeld stellt dies eine besondere Hürde dar. Viele Daten sind entweder aufwendig zu anonymisieren, zu pseudonymisieren oder müssen speziell annotiert werden, um für die eigentliche Entwicklung des Algorithmus Verwendung finden zu können. Sind die Daten vorhanden, müssen sie häufig extrahiert, transformiert und wieder geladen werden; dies geschieht i. d. R. in der sog. ETL-pipeline (ETL=Extract, Transform, Load), einem automatischen Prozess, um diesen zeitaufwendigen Vorgang nicht ständig händisch durchführen zu müssen.
Innerhalb der Modellierung wird eine große Anzahl an verschiedenen Algorithmen oder Modellen ausprobiert. Dieser Teil des Prozesses ist oftmals besonders aufwendig. Zur Beschleunigung, zur Vereinfachung und um den Fokus auf die Auswertung legen zu können, wurde das sog. Automated Machine Learning (AutoML) entwickelt.7 Hierbei können eine Vielzahl von Algorithmen automatisiert nacheinander ausprobiert und miteinander verglichen werden. Auf diese Art und Weise können mögliche Kandidaten für das weitere Finetuning leichter gefunden werden.
In der Evaluationsphase geht es darum, den besten Algorithmus zu identifizieren. Dies geschieht im Regelfall durch eine Vielzahl verschiedener Messwerte, die verglichen werden. Auch an dieser Stelle wird der Business-Case zur Entscheidungsfindung verwendet. So kann es in einem Fall besonders wichtig sein, dass der Algorithmus nur diejenigen Fälle findet, bei denen ein bestimmter Parameter mit an Sicherheit grenzender Wahrscheinlichkeit gegeben ist, sodass das Augenmerk auf Precision liegt. In anderen Fällen hingegen liegt der Schwerpunkt darauf, keinen einzigen Fall zu übersehen und es wird auf den Recall fokussiert. Anhand des Business-Case muss also festgelegt werden, ob Precision oder Recall wichtiger ist. Precision und Recall sind neben dem harmonischen Mittel der beiden, welches auch F1-Score genannt wird, die zumeist genutzten Metriken:

True Positives sind Fälle, in denen der Algorithmus eine Vorhersage getroffen hat, die korrekt ist. False Positives sind Fälle, in denen der Algorithmus vorhergesagt hat, dass ein Umstand gegeben ist, der in Wahrheit nicht vorliegt. False Negatives sind die Fälle, in denen der Algorithmus vorhergesagt hat, der Umstand liege nicht vor, in Wahrheit liegt er allerdings vor.
Wurde der beste Algorithmus beim Durchlaufen der beschriebenen Prozesse sicher identifiziert, so wird dieser als Release-Candidate ausgewählt und deployed, also in das Produkt überführt. Genau an dieser Stelle kommt das Pendant zu DevOps ins Spiel: MLOps. MLOps ist eine Kombination aus Machine Learning und DevOps. Auch hier geht es unter anderem darum, den Automatisierungsgrad zu maximieren, um schnell und einfach den Algorithmus zu entwickeln und in die Produktionsumgebung überführen zu können.
Trotz vieler Gemeinsamkeiten zwischen agiler Software- und agiler KI-Produktentwicklung, wie das Vorhandensein eines starken Teams, erscheint Letztere an manchen Stellen noch etwas komplexer. Im nachfolgenden Abschnitt betrachten wir das KI-Projektteam etwas näher.
3. Das KI-Projektteam
Ohne das passende Team kann auch ein KI-Projekt nicht erfolgreich abgeschlossen werden. Für die Entwicklung der Machine-Learning-Komponente der Expert-Solution CaseWorx von Wolters Kluwer8, bestand das Projektteam aus ganz unterschiedlichen Rollen.
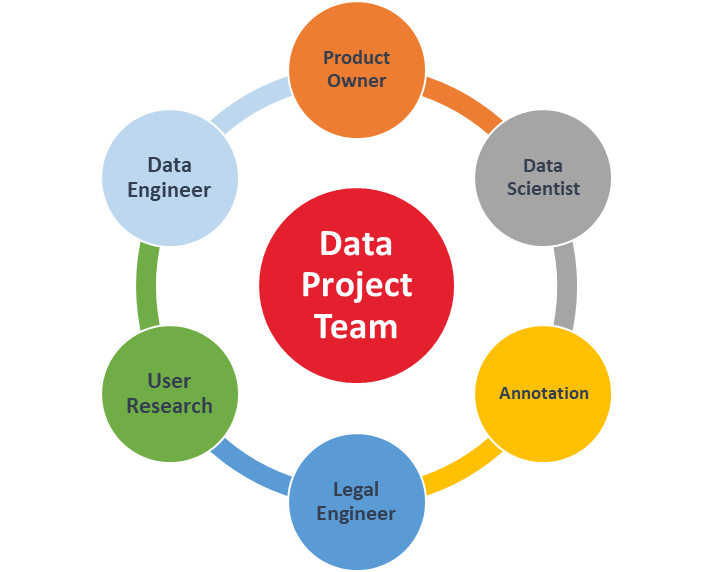
User Research (Nutzerforschung) spielt nicht nur innerhalb der Discovery und Design-Phase des Lean Product Cycle eine große Rolle, sondern auch in allen anderen. Die Nutzerforschung hilft dabei, zu verstehen, was der Nutzer möchte, ob Funktionen im Produkt nützlich sind und insbesondere auch den Erwartungen entsprechen. Der Data Engineer ist besonders im Stadium der Datenvorbereitung involviert und führt bspw. die Datenaufbereitung durch. Der Data Scientist führt die Experimente durch, um den bestmöglichen Algorithmus zu finden, zu optimieren und für die Produktion vorzubereiten.
Nicht zu unterschätzen ist überdies die Arbeit des Annotations-Teams, das häufig „in Vorleistung treten“ muss. Zunächst gilt es, den Datensatz mit Anmerkungen zu versehen, um überhaupt Modelle darauf trainieren zu können. Dies kann etwa dazu führen, dass in einem Projekt in annähernd 20.000 Dokumenten die beteiligten Parteien markiert werden, um ein Extraktionsmodell für diese zu trainieren.
Aber auch die Funktion des Legal Engineers und Product Owners kann leicht unterschätzt werden.
3.1. Legal Engineer in der agilen Produktentwicklung
Im juristischen Umfeld entstand in neuerer Zeit eine Berufsbezeichnung, die sich an der Schnittstelle zwischen Informatik bzw. Softwareentwicklung und dem juristischen Arbeitsumfeld ansiedelt: der Legal Engineer.
Ein Legal Engineer vereint in der Regel juristisches (Prozess-)Wissen mit technischem Verständnis, um bspw. in der Lage zu sein, juristische Prozesse zu automatisieren. Je nachdem, in welchem („Unternehmens“-) Umfeld der Legal Engineer arbeitet, kann die Tätigkeit sehr unterschiedlich ausfallen, weswegen das Berufsbild des Legal Engineer gerne auch sehr unterschiedlich beschrieben wird.9
In der agilen Produktentwicklung tritt der Legal Engineer oft auch als Product Owner auf. In dieser Funktion bringt er die Kundensicht mit in das Team und hilft dabei, die Prioritäten auf den passenden Businessfokus festzulegen.
Im KI-Projekt ist er häufig auch derjenige, der die ersten Ergebnisse prüft, um festzustellen, ob die Qualität der Algorithmen ausreichend ist und im nächsten Schritt die Qualität gemeinsam mit dem Kunden evaluiert.
3.2. Besonderheiten bei der Entwicklung im juristischen Umfeld
Nach den Grundsätzen der agilen KI-Entwicklung wenden wir uns nun den Besonderheiten im juristischen Umfeld zu.
Auf der einen Seite gibt es die regulatorischen Anforderungen an die Software selbst. Diese können beispielsweise darin bestehen, dass es sich um eine High-Risk-Applikation i. S. d. AI Acts handelt, da Richter sie einsetzen, um ihre Fälle zu lösen.10 Verbunden damit werden in nicht allzu ferner Zukunft voraussichtlich besondere Anforderungen an einzelne Elemente der KI-Produktentwicklung gestellt werden11:
- Qualität der verwendeten Datensätze
- technische Dokumentation und Aufzeichnungspflicht
- Transparenz und Bereitstellung von Informationen für Nutzer
- menschliche Aufsicht
- Robustheit
- Genauigkeit
- Cybersicherheit
Auf der anderen Seite sind es jedoch auch Anforderungen der Nutzer selbst, die ihrerseits ggf. besonderen Regelungen unterworfen sind. So legt § 43 S. 1 BRAO fest, dass der Rechtsanwalt seinen Beruf gewissenhaft auszuüben hat. Wird aufgrund eines Black-Box-Models (bspw. ein Deep Neural Network) dem Rechtsanwalt lediglich ein Ergebnis geliefert, bei dem ein Verständnis, wie es dazu gekommen ist, nicht gegeben ist (fehlende Explainability vorausgesetzt), so könnte man hinterfragen, ob die Nichtüberprüfbarkeit dazu führen könnte, dass sich der Rechtsanwalt nicht gewissenhaft verhält.12
Daher besteht ein für Rechtsanwälte essentieller Teil der Entwicklungsarbeit darin, diese Erklärbarkeit umzusetzen. Das noch eher in den Kinderschuhen steckende Themenfeld trägt den Namen Explainable AI und soll gerade bei komplexen neuronalen Modellen mit unterschiedlichen Ansätzen Erklärungen zur Überprüfung und dem Verständnis der Ergebnisse liefern.
Schließlich – und das ist gerade bei KI-Projekten ein großes Problem – gilt es, über die Erwartungshaltung an die Qualität des Algorithmus zu sprechen. Der anfängliche Erwartungshorizont in KI-Projekten ist oftmals der, dass sowohl 100% Precision als auch 100% Recall erreicht werden sollen, denn nur dann werden alle Fälle korrekt erfasst. Allerdings ist ein Erreichen von 100 % in beiden Bereichen zugleich (in der Regel sogar in einem der Bereiche) eher unwahrscheinlich. Die Erwartungen müssen kanalisiert und in andere Lösungswege überführt werden. Auch der Umgang mit den Erwartungen der Kunden ist bei der User Experience mit einzubeziehen, denn gerade so kann erreicht werden, dass Ergebnisse, die nicht zu 100% korrekt sind, leicht identifiziert, korrigiert und zu einer gezielten Interaktion des Kunden führen können.
Geht es beispielsweise darum, ein Fälligkeitsdatum aus einem Dokument zu extrahieren und wird es stattdessen in 10 % der Fälle (zusätzlich) ein anderes Datum extrahiert, so mag das auf den ersten Blick falsch sein. Wird das User Interface allerdings so angepasst, dass dem Nutzer gezeigt wird, woher der Text entnommen wird, und gleichzeitig eine einfache Möglichkeit geschaffen, fehlerhafte Werte leicht zu korrigieren, kann die Qualität des Algorithmus dennoch akzeptabel sein. Transparenz und Nutzerführung sind somit besonders wichtig.
4. Fazit
Die Entwicklung von KI-Projekten im juristischen Umfeld in Deutschland ist ein eher junges Feld. Es muss daher an vielen Stellen weitere Überzeugungsarbeit geleistet werden, um das Wissen über die Fähigkeiten dieses aufstrebenden Bereichs zumindest in der juristischen Fachwelt auf ein stabiles Fundament zu stellen. Die Angst, ein Computer, ein Algorithmus oder eine Künstliche Intelligenz könnte den eigenen Beruf übernehmen, besteht insbesondere bei denjenigen, die sich mit dem Thema nur am Rande befassen. Die derzeitige Bewegung im Bereich von Legal Tech in Deutschland wird ihren Teil dazu beitragen, dass juristische KI-Produktentwicklung nicht mehr die Ausnahme sein wird. Gleichzeitig wird KI eingesetzt werden können, um Legal Professionals bei ihrer Arbeit zu unterstützen; ersetzen wird sie diese auf absehbare Zeit eher nicht.
Die beliebtesten Beiträge des Monats
Die Welt der EDRA Media
Die LRZ erscheint bei der EDRA Media GmbH.
EDRA Media ist ein innovativer Verlag,
Veranstalter und Marketingdienstleister auf den
Gebieten des Rechts und der Medizin.
Gesellschafter sind die Edra S.p.A. (LSWR Group)
und Dr. Jochen Brandhoff.
EDRA MEDIA│ Innovation, Sustainability, Resilience